Btrfs design Btrfs 设计
Btrfs is implemented with simple and well known constructs. It should
perform well, but the long term goal of maintaining performance as the
FS system ages and grows is more important than winning a short lived
benchmark. To that end, benchmarks are being used to try to simulate
performance over the life of a filesystem.
Btrfs 是用简单和众所周知的结构实现的。它应该表现良好,但随着文件系统的老化和增长,保持性能的长期目标比赢得短暂的基准测试更重要。为此,基准测试被用来尝试模拟文件系统寿命内的性能。
Btree Data structures B 树数据结构
The Btrfs btree provides a generic facility to store a variety of data
types. Internally it only knows about three data structures: keys,
items, and a block header:
Btrfs btree 提供了一个通用的设施来存储各种数据类型。在内部,它只知道三种数据结构:键、项和块头:
struct btrfs_header {
u8 csum[32];
u8 fsid[16];
__le64 bytenr;
__le64 flags;
u8 chunk_tree_uid[16];
__le64 generation;
__le64 owner;
__le32 nritems;
u8 level;
}
struct btrfs_disk_key {
__le64 objectid;
u8 type;
__le64 offset;
}
struct btrfs_item {
struct btrfs_disk_key key;
__le32 offset;
__le32 size;
}
Upper nodes of the trees contain only [ key, block pointer ] pairs. Tree
leaves are broken up into two sections that grow toward each other.
Leaves have an array of fixed sized items, and an area where item data
is stored. The offset and size fields in the item indicate where in the
leaf the item data can be found. Example:
树的上层节点仅包含 [键,块指针] 对。树叶被分成两个朝向彼此增长的部分。叶子节点具有一个固定大小项的数组,以及存储项数据的区域。项中的偏移和大小字段指示了在叶子节点中可以找到项数据的位置。示例:
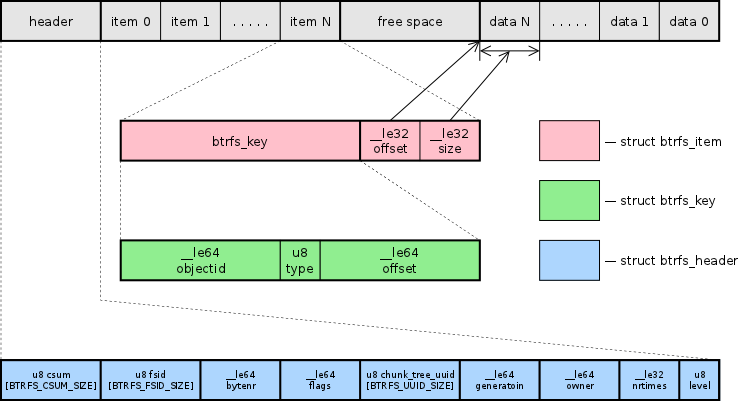
Item data is variably size, and various filesystem data structures are
defined as different types of item data. The type field in struct
btrfs_disk_key indicates the type of data stored in the item.
项数据的大小可变,各种文件系统数据结构被定义为不同类型的项数据。在 struct btrfs_disk_key 中的类型字段指示了存储在项中的数据类型。
The block header contains a checksum for the block contents, the uuid of
the filesystem that owns the block, the level of the block in the tree,
and the block number where this block is supposed to live. These fields
allow the contents of the metadata to be verified when the data is read.
Everything that points to a btree block also stores the generation field
it expects that block to have. This allows Btrfs to detect phantom or
misplaced writes on the media.
区块头包含了区块内容的校验和、拥有该区块的文件系统的 UUID、区块在树中的级别以及该区块应该存放的区块号。这些字段允许在读取数据时验证元数据的内容。指向 btree 区块的所有内容也会存储它期望该区块具有的生成字段。这使得 Btrfs 能够检测介质上的幻影或错位写入。
The checksum of the lower node is not stored in the node pointer to
simplify the FS writeback code. The generation number will be known at
the time the block is inserted into the btree, but the checksum is only
calculated before writing the block to disk. Using the generation will
allow Btrfs to detect phantom writes without having to find and update
the upper node each time the lower node checksum is updated.
为了简化文件系统写回代码,下层节点的校验和不会存储在节点指针中。在将区块插入到 btree 时会知道生成号,但校验和只会在将区块写入磁盘之前计算。使用生成号将允许 Btrfs 在不必每次更新下层节点校验和时找到并更新上层节点的情况下检测到幻影写入。
The generation field corresponds to the transaction id that allocated
the block, which enables easy incremental backups and is used by the
copy on write transaction subsystem.
生成字段对应于分配该区块的事务 ID,这使得容易进行增量备份,并被写时复制事务子系统使用。
Filesystem Data Structures
文件系统数据结构
Each object in the filesystem has an objectid, which is allocated
dynamically on creation. A free objectid is simply a hole in the key
space of the filesystem btree; objectids that don’t already exist in the
tree. The objectid makes up the most significant bits of the key,
allowing all of the items for a given filesystem object to be logically
grouped together in the btree.
文件系统中的每个对象都有一个对象 ID,在创建时动态分配。空闲的对象 ID 只是文件系统 B 树键空间中的一个空洞;这些对象 ID 在树中尚不存在。对象 ID 组成键的最高有效位,允许将给定文件系统对象的所有项在 B 树中逻辑分组在一起。
The offset field of the key stores indicates the byte offset for a
particular item in the object. For file extents, this would be the byte
offset of the start of the extent in the file. The type field stores the
item type information, and has extra room for expanded use.
键的偏移字段指示对象中特定项的字节偏移量。对于文件范围,这将是文件中范围起始处的字节偏移量。类型字段存储项类型信息,并具有用于扩展使用的额外空间。
Inodes 索引节点
Inodes are stored in struct btrfs_inode_item at offset zero in the key,
and have a type value of one. Inode items are always the lowest valued
key for a given object, and they store the traditional stat data for
files and directories. The inode structure is relatively small, and will
not contain embedded file data or extended attribute data. These things
are stored in other item types.
索引节点存储在键的偏移零处的 struct btrfs_inode_item 中,并且具有类型值为一。索引节点项始终是给定对象的键中值最低的项,它们存储文件和目录的传统 stat 数据。索引节点结构相对较小,不包含嵌入的文件数据或扩展属性数据。这些内容存储在其他项类型中。
Files 文件
Small files that occupy less than one leaf block may be packed into the
btree inside the extent item. In this case the key offset is the byte
offset of the data in the file, and the size field of struct btrfs_item
indicates how much data is stored. There may be more than one of these
per file.
占用少于一个叶块的小文件可以打包到范围项内的 btree 中。在这种情况下,键偏移量是文件中数据的字节偏移量,struct btrfs_item 的大小字段指示存储了多少数据。一个文件中可能有多个这样的项。
Larger files are stored in extents. struct btrfs_file_extent_item
records a generation number for the extent and a [ disk block, disk num
blocks ] pair to record the area of disk corresponding to the file.
Extents also store the logical offset and the number of blocks used by
this extent record into the extent on disk. This allows Btrfs to satisfy
a rewrite into the middle of an extent without having to read the old
file data first. For example, writing 1MB into the middle of a existing
128MB extent may result in three extent records:
较大的文件存储在范围内。struct btrfs_file_extent_item 记录了范围的生成编号和一个[磁盘块,磁盘块数]对,用于记录与文件对应的磁盘区域。范围还存储了逻辑偏移量和用于将此范围记录写入磁盘的块数。这使得 Btrfs 能够在不必先读取旧文件数据的情况下满足对范围中间的重写。例如,将 1MB 写入现有的 128MB 范围中间可能会导致三个范围记录:
[ old extent: bytes 0-64MB ], [ new extent 1MB ], [ old extent: bytes 65MB – 128MB]
File data checksums are stored in a dedicated btree in a struct
btrfs_csum_item. The offset of the key corresponds to the byte number of
the extent. The data is checksummed after any compression or encryption
is done and it reflects the bytes sent to the disk.
文件数据校验和存储在 struct btrfs_csum_item 中的专用 btree 中。键的偏移量对应于范围的字节编号。数据在执行任何压缩或加密后进行校验和,并且它反映了发送到磁盘的字节。
A single item may store a number of checksums. struct btrfs_csum_items
are only used for file extents. File data inline in the btree is covered
by the checksum at the start of the btree block.
单个项目可以存储多个校验和。struct btrfs_csum_items 仅用于文件范围。B 树中内联的文件数据由 B 树块开头的校验和覆盖。
Directories 目录
Directories are indexed in two different ways. For filename lookup,
there is an index comprised of keys:
目录有两种不同的索引方式。对于文件名查找,有一个由键组成的索引:
Directory Objectid 目录对象 ID |
BTRFS_DIR_ITEM_KEY |
64 bit filename hash 64 位文件名哈希 |
The default directory hash used is crc32c, although other hashes may be
added later on. A flags field in the super block will indicate which
hash is used for a given FS.
默认目录哈希使用的是 crc32c,尽管以后可能会添加其他哈希。 超级块中的标志字段将指示对于给定的文件系统使用哪个哈希。
The second directory index is used by readdir to return data in inode
number order. This more closely resembles the order of blocks on disk
and generally provides better performance for reading data in bulk
(backups, copies, etc). Also, it allows fast checking that a given inode
is linked into a directory when verifying inode link counts. This index
uses an additional set of keys:
readdir 使用第二个目录索引以 inode 编号顺序返回数据。这更接近磁盘上块的顺序,通常为批量读取数据(备份、复制等)提供更好的性能。此外,它允许快速检查给定的 inode 是否链接到目录中,从而验证 inode 链接计数。此索引使用额外的一组键:
Directory Objectid 目录对象 ID |
BTRFS_DIR_INDEX_KEY |
Inode Sequence number Inode 序列号 |
The inode sequence number comes from the directory. It is increased each
time a new file or directory is added.
i 节点序列号来自目录。每次添加新文件或目录时都会增加。
Reference Counted Extents
引用计数的范围
Reference counting is the basis for the snapshotting subsystems. For
every extent allocated to a btree or a file, Btrfs records the number of
references in a struct btrfs_extent_item. The trees that hold these
items also serve as the allocation map for blocks that are in use on the
filesystem. Some trees are not reference counted and are only protected
by a copy on write logging. However, the same type of extent items are
used for all allocated blocks on the disk.
引用计数是快照子系统的基础。对于分配给 btree 或文件的每个范围,Btrfs 在 struct btrfs_extent_item 中记录引用的数量。保存这些项的树也用作文件系统上正在使用的块的分配图。一些树没有引用计数,只受写时复制日志的保护。然而,所有磁盘上分配的块都使用相同类型的范围项。
A reasonably comprehensive description of the way that references work
can be found in this email from Josef
Bacik.
可以在 Josef Bacik 的电子邮件中找到对引用工作方式的相当全面的描述。
Extent Block Groups 范围块组
Extent block groups allow allocator optimizations by breaking the disk
up into chunks of 256MB or more. For each chunk, they record information
about the number of blocks available. Files and directories will have a
preferred block group which they try first for allocations.
范围块组通过将磁盘分成 256MB 或更大的块来实现分配器优化。对于每个块,它们记录有关可用块数量的信息。文件和目录将有一个首选块组,它们首先尝试进行分配。
Block groups have a flag that indicate if they are preferred for data or
metadata allocations, and at mkfs time the disk is broken up into
alternating metadata (33% of the disk) and data groups (66% of the
disk). As the disk fills, a group’s preference may change back and
forth, but Btrfs always tries to avoid intermixing data and metadata
extents in the same group. This substantially improves fsck throughput,
and reduces seeks during writeback while the FS is mounted. It does
slightly increase the seeks while reading.
块组有一个标志,指示它们是否首选用于数据或元数据分配,并且在 mkfs 时间,磁盘被分成交替的元数据(磁盘的 33%)和数据组(磁盘的 66%)。随着磁盘填满,组的首选项可能来回变化,但 Btrfs 总是尽量避免在同一组中混合数据和元数据范围。这大大提高了 fsck 的吞吐量,并减少了在挂载文件系统时写回期间的寻道。这确实会增加读取时的寻道。
Extent Trees and DM integration
范围树和 DM 集成
The Btrfs extent trees are intended to divide up the available storage
into a number of flexible allocation policies. Each extent tree owns a
section of the underlying disk, and they can be assigned to a collection
of (or a single) tree roots, directories or inodes. Policies will direct
how a given allocation is spread across the extent trees available,
allowing the admin to direct which parts of the filesystem are striped,
mirrored or confined to a given device.
Btrfs 范围树旨在将可用存储划分为多种灵活的分配策略。每个范围树拥有底层磁盘的一部分,并且它们可以分配给一组(或单个)树根、目录或索引节点。策略将指导如何将给定的分配分布到可用的范围树中,允许管理员指导文件系统的哪些部分是条带化的、镜像化的或限制在给定设备上。
Btrfs will try to tie in with DM in order to easily manage large pools
of storage. The basic idea is to have at least one extent tree per
spindle, and then allow the admin to assign those extent trees to
subvolumes, directories or files.
Btrfs 将尝试与 DM 结合,以便轻松管理大型存储池。基本思想是每个主轴至少有一个范围树,然后允许管理员将这些范围树分配给子卷、目录或文件。
Explicit Back References
显式反向引用
Back references have three main goals:
反向引用有三个主要目标:
Differentiate between all holders of references to an extent so that when a reference is dropped we can make sure it was a valid reference before freeing the extent.
区分所有引用持有者的程度,以便在引用被丢弃时,我们可以确保在释放范围之前它是一个有效的引用。Provide enough information to quickly find the holders of an extent if we notice a given block is corrupted or bad.
提供足够的信息,以便在我们注意到给定块已损坏或有问题时,快速找到范围的持有者。Make it easy to migrate blocks for FS shrinking or storage pool maintenance. This is actually the same as #2, but with a slightly different use case.
使块易于迁移,以便进行文件系统收缩或存储池维护。这实际上与#2 相同,但具有略有不同的用例。
File Extent Backrefs 文件扩展名反向引用
File extents can be referenced by:
文件扩展可以被引用为:
Multiple snapshots, subvolumes, or different generations in one subvol
在一个子卷中的多个快照、子卷或不同的生成Different files inside a single subvolume
单个子卷内的不同文件Different offsets inside a file
文件内的不同偏移量
Note 注意
The remainder of this section refers to the extent_ref_v0 structure, which is not used on current btrfs filesystems.
本节的其余部分涉及 extent_ref_v0 结构,该结构在当前的 btrfs 文件系统上不使用。
The extent ref structure has fields for:
扩展 ref 结构具有以下字段:
Objectid of the subvolume root
子卷根的 ObjectidGeneration number of the tree holding the reference
持有引用的树的生成编号objectid of the file holding the reference
文件持有引用的对象标识符offset in the file corresponding to the key holding the reference
文件中对应于持有引用的键的偏移量
When a file extent is allocated the fields are filled in:
当分配文件范围时,填充字段:
(root objectid, transaction id, inode objectid, offset in file)
(根对象 ID,事务 ID,inode 对象 ID,文件中的偏移量)
When a leaf is cow’d new references are added for every file extent
found in the leaf. It looks the same as the create case, but the
transaction id will be different when the block is cow’d.
当叶子被复制时,为叶子中找到的每个文件范围添加新的引用。它看起来与创建情况相同,但在块被复制时事务 ID 将不同。
(root objectid, transaction id, inode objectid, offset in file)
(根对象 ID,事务 ID,inode 对象 ID,文件中的偏移量)
When a file extent is removed either during snapshot deletion or file
truncation, the corresponding back reference is found by searching for:
当文件范围在快照删除或文件截断期间被移除时,通过搜索以下内容找到相应的后向引用:
(btrfs_header_owner(leaf), btrfs_header_generation(leaf), inode objectid, offset in file)
(btrfs_header_owner(叶子), btrfs_header_generation(叶子), inode 对象 ID, 文件中的偏移量)
Btree Extent Backrefs B 树范围后向引用
Btree extents can be referenced by:
B 树范围可以被引用:
Different subvolumes 不同的子卷
Different generations of the same subvolume
相同子卷的不同世代
Storing sufficient information for a full reverse mapping of a btree
block would require storing the lowest key of the block in the backref,
and it would require updating that lowest key either before write out or
every time it changed.
存储足够的信息以完全反向映射 btree 块将需要在 backref 中存储块的最低键,并且需要在写出之前或每次更改时更新该最低键。
Instead, the objectid of the lowest key is stored along with the level
of the tree block. This provides a hint about where in the btree the
block can be found. Searches through the btree only need to look for a
pointer to that block, and they stop one level higher than the level
recorded in the backref.
相反,存储最低键的 objectid 以及树块的级别。这提供了有关在 btree 中可以找到块的位置的提示。通过 btree 的搜索只需要查找指向该块的指针,并且它们停在 backref 中记录的级别的上一级。
Some btrees do not do reference counting on their extents. These include
the extent tree and the tree of tree roots. Backrefs for these trees
always have a generation of zero.
一些 btree 不对其范围进行引用计数。这些包括范围树和树根的树。这些树的 backref 总是具有零的生成。
When a tree block is created, back references are inserted:
当创建树块时,会插入反向引用:
(root objectid, transaction id or zero, level, lowest objectid)
(根对象 id、事务 id 或零、级别、最低对象 id)
The level is stored in the objectid slot of the backref to differentiate
between Btree back references and file data back references. The highest
possible level is 255, and the lowest possible file objectid has been
raised to 256. So, if the objectid field in the back reference is less
than 256, it corresponds to a Btree block.
级别存储在反向引用的对象 id 槽中,以区分 B 树反向引用和文件数据反向引用。最高可能级别为 255,最低可能文件对象 id 已提高至 256。因此,如果反向引用中的对象 id 字段小于 256,则对应于 B 树块。
When a tree block is cow’d in a reference counted root, new back
references are added for all the blocks it points to:
当树块在引用计数根中被 cow’d 时,为其指向的所有块添加新的反向引用:
(root objectid, transaction id, level, lowest objectid)
(根对象 id,事务 id,级别,最低对象 id)
Because the lowest_key_objectid and the level are just hints they are
not used when backrefs are deleted. When a snapshot is created a new
reference is taken directly on the root block. This means the owner
field of the root block may be different from the objectid of the
snapshot. So, when dropping references on tree roots, the objectid of
the root structure is always used. When a backref is deleted:
因为最低键对象 id 和级别只是提示,它们在删除反向引用时不会被使用。创建快照时,直接在根块上获取新的引用。这意味着根块的所有者字段可能与快照的对象 id 不同。因此,在删除树根上的引用时,始终使用根结构的对象 id。当删除反向引用时:
if backref was for a tree root:
root_objectid = root->root_key.objectid
else
root_objectid = btrfs_header_owner(parent)
(root_objectid, btrfs_header_generation(parent) or zero, 0, 0)
(root_objectid, btrfs_header_generation(parent) 或零, 0, 0)
Back Reference Key Construction
反向引用键构造
Back references have four fields, each 64 bits long. This is hashed into
a single 64 bit number and placed into the key offset. The key objectid
corresponds to the first byte in the extent, and the key type is set to
BTRFS_EXTENT_REF_KEY.
反向引用有四个字段,每个字段长度为 64 位。这被哈希成一个 64 位的数字,并放入键偏移量中。键对象 ID 对应于范围中的第一个字节,键类型设置为 BTRFS_EXTENT_REF_KEY。
Hash overflows on the offset field are handled by adding one to the
calculated hash and searching forward. The searching stops when the
correct back reference structure is found or
散列溢出在偏移字段上通过将计算的散列加一并向前搜索来处理。当找到正确的后向引用结构或搜索停止
Snapshots and Subvolumes
快照和子卷
Subvolumes are basically a named btree that holds files and directories.
They have inodes inside the tree of tree roots and can have non-root
owners and groups. Subvolumes can be given a quota of blocks, and once
this quota is reached no new writes are allowed. All of the blocks and
file extents inside of subvolumes are reference counted to allow
snapshotting. Up to 264 subvolumes may be created on the FS.
子卷基本上是一个包含文件和目录的命名 b 树。它们在树根的树中有索引节点,并且可以有非根所有者和组。子卷可以被分配一个块的配额,一旦达到这个配额,就不允许新的写入。子卷内的所有块和文件范围都是引用计数的,以允许快照。在 FS 上最多可以创建 2 个子卷。
Snapshots are identical to subvolumes, but their root block is initially
shared with another subvolume. When the snapshot is taken, the reference
count on the root block is increased, and the copy on write transaction
system ensures changes made in either the snapshot or the source
subvolume are private to that root. Snapshots are writable, and they can
be snapshotted again any number of times. If read only snapshots are
desired, their block quota is set to one at creation time.
快照与子卷相同,但其根块最初与另一个子卷共享。拍摄快照时,根块上的引用计数会增加,并且写时复制事务系统确保在快照或源子卷中进行的更改对该根是私有的。快照是可写的,并且可以再次进行任意次数的快照。如果需要只读快照,则在创建时将其块配额设置为 1。
Btree Roots B 树根
Each Btrfs filesystem consists of a number of tree roots. A freshly
formatted filesystem will have roots for:
每个 Btrfs 文件系统由多个树根组成。新格式化的文件系统将具有以下根:
The tree of tree roots
树根的树The tree of allocated extents
已分配范围的树The default subvolume tree
默认子卷树
The tree of tree roots records the root block for the extent tree and
the root blocks and names for each subvolume and snapshot tree. As
transactions commit, the root block pointers are updated in this tree to
reference the new roots created by the transaction, and then the new
root block of this tree is recorded in the FS super block.
树根树记录了范围树的根块以及每个子卷和快照树的根块和名称。随着事务提交,根块指针在此树中更新,以引用事务创建的新根,然后此树的新根块记录在 FS 超级块中。
The tree of tree roots acts as a directory of all the other trees on the
filesystem, and it has directory items recording the names of all
snapshots and subvolumes in the FS. Each snapshot or subvolume has an
objectid in the tree of tree roots, and at least one corresponding
struct btrfs_root_item. Directory items in the tree map names of
snapshots and subvolumes to these root items. Because the root item key
is updated with every transaction commit, the directory items reference
a generation number of (u64)-1, which tells the lookup code to find the
most recent root available.
树根树充当文件系统中所有其他树的目录,它具有记录 FS 中所有快照和子卷名称的目录项。每个快照或子卷在树根树中具有一个对象 ID,并且至少有一个相应的 struct btrfs_root_item。树中的目录项将快照和子卷的名称映射到这些根项。由于每个事务提交时更新根项键,因此目录项引用(u64)-1 的生成编号,告诉查找代码找到最新的可用根。
The extent trees are used to manage allocated space on the devices. The
space available can be divided between a number of extent trees to
reduce lock contention and give different allocation policies to
different block ranges.
范围树用于管理设备上分配的空间。可用空间可以在多个范围树之间划分,以减少锁争用并为不同的块范围提供不同的分配策略。
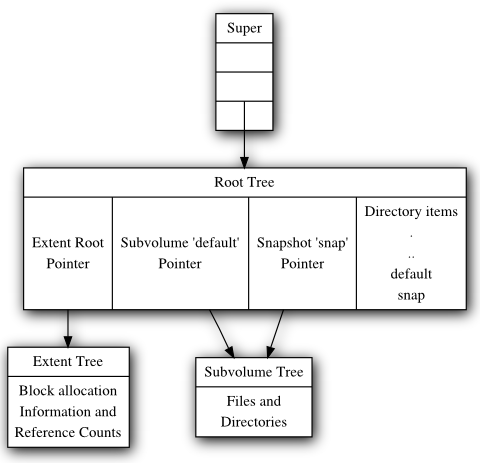
The diagram below depicts a collection of tree roots. The super block
points to the root tree, and the root tree points to the extent trees
and subvolumes. The root tree also has a directory to map subvolume
names to struct btrfs_root_items in the root tree. This filesystem has
one subvolume named ‘default’ (created by mkfs), and one snapshot of
‘default’ named ‘snap’ (created by the admin some time later). In this
example, ‘default’ has not changed since the snapshot was created and so
both point tree to the same root block on disk.
下面的图表描述了一组树根。超级块指向根树,根树指向范围树和子卷。根树还有一个目录,将子卷名称映射到根树中的 struct btrfs_root_items。这个文件系统有一个名为“default”的子卷(由 mkfs 创建),以及一个名为“snap”的“default”快照(由管理员在稍后的某个时间创建)。在这个例子中,“default”自创建快照以来没有发生变化,因此两者都指向磁盘上相同的根块。
Copy on Write Logging
写时复制日志
Data and metadata in Btrfs are protected with copy on write logging
(COW). Once the transaction that allocated the space on disk has
committed, any new writes to that logical address in the file or btree
will go to a newly allocated block, and block pointers in the btrees and
super blocks will be updated to reflect the new location.
Btrfs 中的数据和元数据受到写时复制日志(COW)的保护。一旦在磁盘上分配了空间的事务提交,对文件或 B 树中的逻辑地址的任何新写入都将进入新分配的块,并且 B 树和超级块中的块指针将被更新以反映新位置。
Some of the btrfs trees do not use reference counting for their
allocated space. This includes the root tree, and the extent trees. As
blocks are replaced in these trees, the old block is freed in the extent
tree. These blocks are not reused for other purposes until the
transaction that freed them commits.
一些 btrfs 树不使用引用计数来管理它们分配的空间。这包括根树和范围树。当这些树中的块被替换时,在范围树中释放旧块。这些块直到释放它们的事务提交后才能被重新用于其他目的。
All subvolume (and snapshot) trees are reference counted. When a COW
operation is performed on a btree node, the reference count of all the
blocks it points to is increased by one. For leaves, the reference
counts of any file extents in the leaf are increased by one. When the
transaction commits, a new root pointer is inserted in the root tree for
each new subvolume root. The key used has the form:
所有子卷(和快照)树都是引用计数的。当在 btree 节点上执行 COW 操作时,它指向的所有块的引用计数都会增加一。对于叶子节点,叶子中的任何文件范围的引用计数都会增加一。当事务提交时,为每个新的子卷根在根树中插入一个新的根指针。使用的键的形式为:
Subvolume inode number 子卷 inode 编号 |
BTRFS_ROOT_ITEM_KEY |
Transaction ID 交易 ID |
The updated btree blocks are all flushed to disk, and then the super
block is updated to point to the new root tree. Once the super block has
been properly written to disk, the transaction is considered complete.
At this time the root tree has two pointers for each subvolume changed
during the transaction. One item points to the new tree and one points
to the tree that existed at the start of the last transaction.
更新的 btree 块都被刷新到磁盘,然后超级块被更新指向新的根树。一旦超级块被正确写入磁盘,交易被视为完成。此时,根树对于交易期间更改的每个子卷都有两个指针。一个指向新树,一个指向上次交易开始时存在的树。
Any time after the commit finishes, the older subvolume root items may
be removed. The reference count on the subvolume root block is lowered
by one. If the reference count reaches zero, the block is freed and the
reference count on any nodes the root points to is lowered by one. If a
tree node or leaf can be freed, it is traversed to free the nodes or
extents below it in the tree in a depth first fashion.
在提交完成后的任何时间,旧的子卷根项目可能会被移除。子卷根块上的引用计数减少一。如果引用计数达到零,该块将被释放,并且根指向的任何节点的引用计数减少一。如果可以释放树节点或叶子,它将以深度优先的方式遍历以释放树中它下面的节点或范围。
The traversal and freeing of the tree may be done in pieces by inserting
a progress record in the root tree. The progress record indicates the
last key and level touched by the traversal so the current transaction
can commit and the traversal can resume in the next transaction. If the
system crashes before the traversal completes, the progress record is
used to safely delete the root on the next mount.
树的遍历和释放可以通过在根树中插入进度记录来分段完成。进度记录指示了遍历所触及的最后一个键和级别,因此当前事务可以提交,遍历可以在下一个事务中恢复。如果系统在遍历完成之前崩溃,进度记录将用于在下次挂载时安全删除根。
Ohad Rodeh presented this reference counted snapshot algorithm at the
2007 Linux Filesystem and Storage Workshop:
Ohad Rodeh 在 2007 年的 Linux 文件系统和存储研讨会上介绍了这个引用计数快照算法:
Slides: LinuxFS_Workshop.pdf
幻灯片:LinuxFS_Workshop.pdf
Paper: Btree_TOS.pdf 文件:Btree_TOS.pdf
The Btrfs snapshotting implementation is based on the ideas he
presented.
Btrfs 快照实现是基于他提出的想法。
Btrfsck
The filesystem checking utility is a crucial tool, but it can be a major
bottleneck in getting systems back online after something has gone
wrong. Btrfs aims to be tolerant of invalid metadata, and will avoid
using metadata it determines to be incorrect. The disk format allows
Btrfs to deal with most corruptions at run time, without crashing the
system and without requiring offline filesystem checking.
文件系统检查实用程序是一个至关重要的工具,但在系统出现问题后重新上线时可能成为一个主要瓶颈。Btrfs 旨在容忍无效的元数据,并将避免使用它认为不正确的元数据。磁盘格式允许 Btrfs 在运行时处理大多数损坏,而无需使系统崩溃并且无需离线文件系统检查。
An offline btrfsck is being developed, in part to help verify the
filesystem during testing, and as an emergency tool to make sure the
filesystem is safe for mounting. The existing tool only verifies the
extent allocation maps, making sure that reference counts are correct
and that all extents are accounted for. If the extent maps are correct,
there is no risk of incorrectly writing over existing data or metadata
as blocks are allocated for new use.
正在开发离线 btrfsck,部分原因是为了在测试期间验证文件系统,并作为一种紧急工具,以确保文件系统可以安全挂载。现有工具仅验证范围分配图,确保引用计数正确并且所有范围都有记录。如果范围图正确,那么在为新用途分配块时不会错误地覆盖现有数据或元数据。
btrfsck is able to read metadata in roughly disk order. As it scans the
btrees on disk, it collects the locations of nodes and leaves and pulls
them from the disk in large sequential batches. For the most part,
btrfsck is bound by the sequential read throughput of the storage, and
it is able to take advantage of multi-spindle arrays. The price paid for
the extra speed is more ram. Btrfsck uses about 3x more ram than
ext2fsck.
btrfsck 能够按照大致的磁盘顺序读取元数据。在扫描磁盘上的 b 树时,它会收集节点和叶子的位置,并以大批量的顺序从磁盘中提取它们。在大多数情况下,btrfsck 受到存储的顺序读取吞吐量的限制,并且能够利用多个磁盘阵列。为了获得额外的速度,需要付出更多的内存。与 ext2fsck 相比,btrfsck 使用的内存大约多 3 倍。